flowchart TD
A["All Data Points"] --> B{"Random Split 1"}
B -->|Left| C["Normal Cluster"]
B -->|Right| D{"Random Split 2"}
D -->|Left| E["Normal Subclusters"]
D -->|Right| F["🚨 ANOMALY ISOLATED"]
style F fill:#FFCDD2,stroke:#C62828
style C fill:#E8F5E9,stroke:#4CAF50
style E fill:#E8F5E9,stroke:#4CAF50
The Watchful Robotic Owl
Advanced AI Vigilance in the Jungle
Introduction: A Heightened Threat in the Jungle
Deep within the nature reserve, unexplained disturbances stir the night.
Tracks appear where no animals should tread. Camera traps vanish without a trace. Poachers, illegal loggers, and other intruders encroach upon the habitat, threatening to disrupt the fragile balance of life.
The Robotic Owl—already proficient in basic vision and classification—now faces a far greater challenge: evolving its intelligence to protect the wildlife it has pledged to defend. In this chapter, we explore the advanced AI and ML techniques that enable the Owl to uncover hidden dangers, adapt to shifting threats, and maintain peace across its jungle domain.

Expanded Sensor Fusion: Seeing Beyond the Shadows
To rise to these new challenges, the Owl relies on a suite of enhanced sensors:
TipThe Owl’s Enhanced Senses
| Sensor Type | Purpose | ML Technique |
|---|---|---|
| Infrared | Heat signatures in darkness | CNN + RGB fusion |
| Acoustic | Unusual sounds (chainsaws, voices) | RNN/Transformer |
| Chemical | Atypical scents (fuel, chemicals) | Unsupervised clustering |
Infrared Cameras
- Purpose: Uncover heat signatures in pitch-dark regions or dense foliage.
- ML Angle: Combining (or fusing) IR with standard RGB data bolsters detection accuracy, even under poor lighting.
Acoustic Arrays
- Purpose: Pinpoint unusual sounds—chainsaws, vehicles, hushed voices—in real time.
- ML Angle: Time-series modeling (using RNNs or Transformers) can recognize audio patterns that deviate from typical jungle ambiance.
Chemical / Olfactory Sensors
- Purpose: Sniff out atypical scents, such as spilled fuel or chemical residues left by intruders.
- ML Angle: Unsupervised clustering differentiates routine forest smells from suspicious outliers.

By blending these data streams, the Owl gains a multi-layered understanding of its environment—essential for identifying threats invisible to any single sensor.
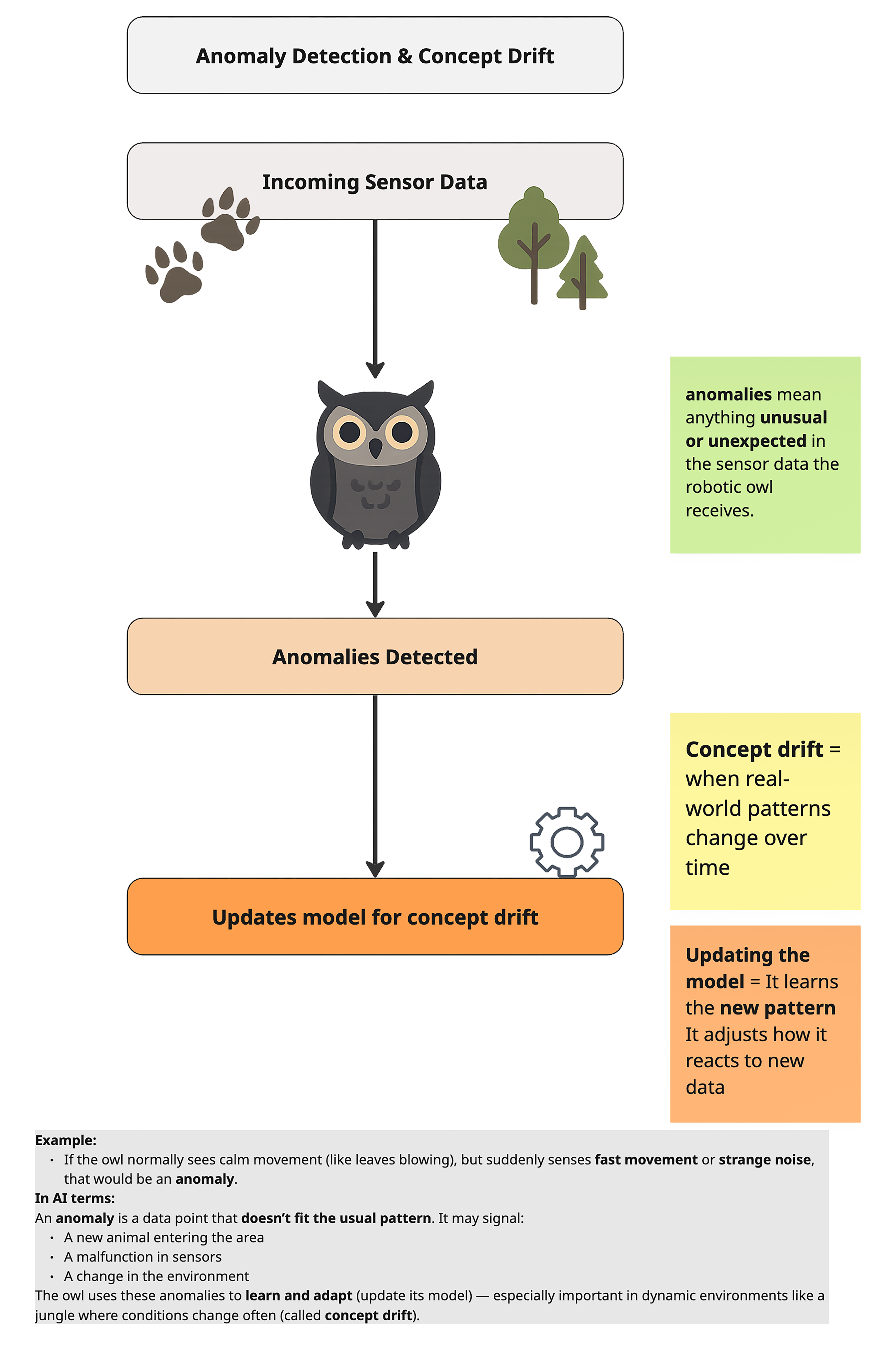
Detecting the Unusual: Anomaly Detection & Concept Drift
Anomaly Detection
- Key Idea: Identify events or signals that don’t match the Owl’s learned “normal” patterns—like midnight noises near a restricted clearing.
- Possible Approaches:
- Isolation Forest: Randomly partition data to isolate outliers.
- Autoencoder: Learns to reconstruct normal sensor data; unusual inputs produce higher reconstruction errors.
- Jungle Example: If the Owl suddenly picks up chain-link rattling or unfamiliar vehicle engines, anomaly detection flags it so the Owl can investigate.
Design Intuition:
In real-world systems, anomaly detection deliberately prioritizes coverage over certainty. The goal is not perfect classification, but early signal discovery. Higher false positives are acceptable initially, because missing rare or novel threats is often more costly than investigating benign alerts. Over time, human feedback and contextual filtering reduce noise without sacrificing sensitivity.
🌲 The Owl’s Isolation Chamber: Isolation Forest Deep Dive
The Owl’s most powerful anomaly detector works on a counterintuitive principle: anomalies are easy to isolate. While normal observations cluster together (requiring many “cuts” to separate), outliers stand alone and can be isolated quickly.
NoteJargon Buster: How Isolation Forest Works
Isolation Forest builds an ensemble of random isolation trees. Each tree:
- Picks a random feature and a random split point.
- Recursively partitions the data until each point is isolated.
- Records the path length (number of splits) needed to isolate each point.
Key Insight: Anomalies require shorter paths because they’re different from most data points. Normal points require longer paths because they’re surrounded by similar neighbors.
The final anomaly score is the average path length across all trees, normalized to a 0–1 scale where higher = more anomalous.
The Jungle Narrative: Spotting the Lone Intruder
Imagine the Owl monitoring 1,000 jungle creatures. Most travel in groups, eat at similar times, and follow predictable routes. But one creature moves alone, at odd hours, in restricted areas. When the Owl’s isolation tree tries to separate this creature from the others, it only takes 2 splits. Normal creatures take 8+ splits. The lone creature is flagged immediately.
TipReal-World Example: Credit Card Fraud Detection
Banks like JPMorgan and Mastercard use Isolation Forest to detect fraudulent transactions.
Why? Because fraud is rare (0.1% of transactions) and unpredictable (new fraud patterns emerge daily). Isolation Forest doesn’t need labeled fraud examples—it simply finds transactions that “stand out” from normal spending behavior: unusual amounts, strange locations, odd timing.
This unsupervised approach catches novel fraud types that supervised models trained on historical fraud would miss.
Technical Spotlight: Isolation Forest in Action
# Python: Isolation Forest for Anomaly Detection
from sklearn.ensemble import IsolationForest
import numpy as np
# 1. Create sample data: 995 normal, 5 anomalous
np.random.seed(42)
normal = np.random.randn(995, 2) # Normal cluster around origin
anomalies = np.random.uniform(-4, 4, (5, 2)) # Scattered outliers
data = np.vstack([normal, anomalies])
# 2. Train Isolation Forest
iso_forest = IsolationForest(contamination=0.005, random_state=42)
iso_forest.fit(data)
# 3. Predict: -1 = anomaly, 1 = normal
predictions = iso_forest.predict(data)
anomaly_indices = np.where(predictions == -1)[0]
print(f"🚨 Detected {len(anomaly_indices)} anomalies")
print(f" Indices: {anomaly_indices.tolist()}")
# Output: Detects the 5 anomalies at indices 995-999
# 4. Get anomaly scores (lower = more anomalous)
scores = iso_forest.decision_function(data)
most_anomalous = np.argmin(scores)
print(f"🔴 Most anomalous point: #{most_anomalous}")Key Insight: The contamination parameter tells the model what fraction of data to expect as anomalies. Set it low (e.g., 0.01) for rare event detection. The decision_function returns raw scores—useful for ranking suspicious cases.
The Owl’s Toolkit: Choosing the Right Weapon
The Robotic Owl has access to many anomaly detection tools, but each has a different purpose. Just as a carpenter wouldn’t use a sledgehammer to hang a picture frame, the Owl must choose the right tool for each job.
NoteJargon Buster: When to Use What?
| Library | Best For | Example Algorithms | Model Size | When to Use |
|---|---|---|---|---|
| scikit-learn | Tabular data, fast prototyping | K-Means, Isolation Forest, Logistic Regression | ~KB | 90% of business ML problems |
| PyTorch / TensorFlow | Neural networks, custom architectures | Autoencoders, CNNs, RNNs | KB–GB | Complex patterns, images, sequences |
| LLM APIs | Text understanding, generation | GPT, Claude, Gemini | 70GB+ (hosted) | Chat, summarization, reasoning |
Rule of thumb: Start with scikit-learn. Only move to PyTorch if scikit-learn can’t capture the complexity. Only use LLMs if you need language understanding.
The Isolation Forest we just saw uses scikit-learn—perfect for tabular data with numeric features. But what if the Owl needs to detect anomalies in more complex patterns? That’s when it reaches for PyTorch and the Autoencoder.
NoteJargon Buster: What is PyTorch?
PyTorch is a deep learning framework that lets you build neural networks from scratch. While scikit-learn provides ready-made algorithms, PyTorch gives you building blocks to construct custom architectures.
| Component | What It Does | Example |
|---|---|---|
| Tensors | Multi-dimensional arrays (like NumPy, but GPU-accelerated) | torch.tensor([1, 2, 3]) |
| Autograd | Automatic differentiation for training | Computes gradients automatically |
| torch.nn | Neural network layers | nn.Linear, nn.Conv2d, nn.Transformer |
| Optimizers | Update weights during training | Adam, SGD |
| DataLoader | Batch and shuffle data | Handles mini-batch training |
When to use PyTorch vs scikit-learn?
| Scenario | Use | Why |
|---|---|---|
| Tabular data, quick prototype | scikit-learn | Simpler, faster, interpretable |
| Complex patterns, 100+ features | PyTorch (Autoencoder) | Learns multi-dimensional correlations |
| Images, audio, sequences | PyTorch (CNN, RNN) | Neural networks excel at spatial/temporal patterns |
| Custom research architecture | PyTorch | Full flexibility to build anything |
The PyTorch Pattern:
# PyTorch follows a similar pattern to scikit-learn
import torch.nn as nn
model = nn.Sequential(nn.Linear(100, 50), nn.ReLU(), nn.Linear(50, 10)) # 1. Define
optimizer = torch.optim.Adam(model.parameters()) # 2. Choose optimizer
# 3. Training loop: forward → loss → backward → step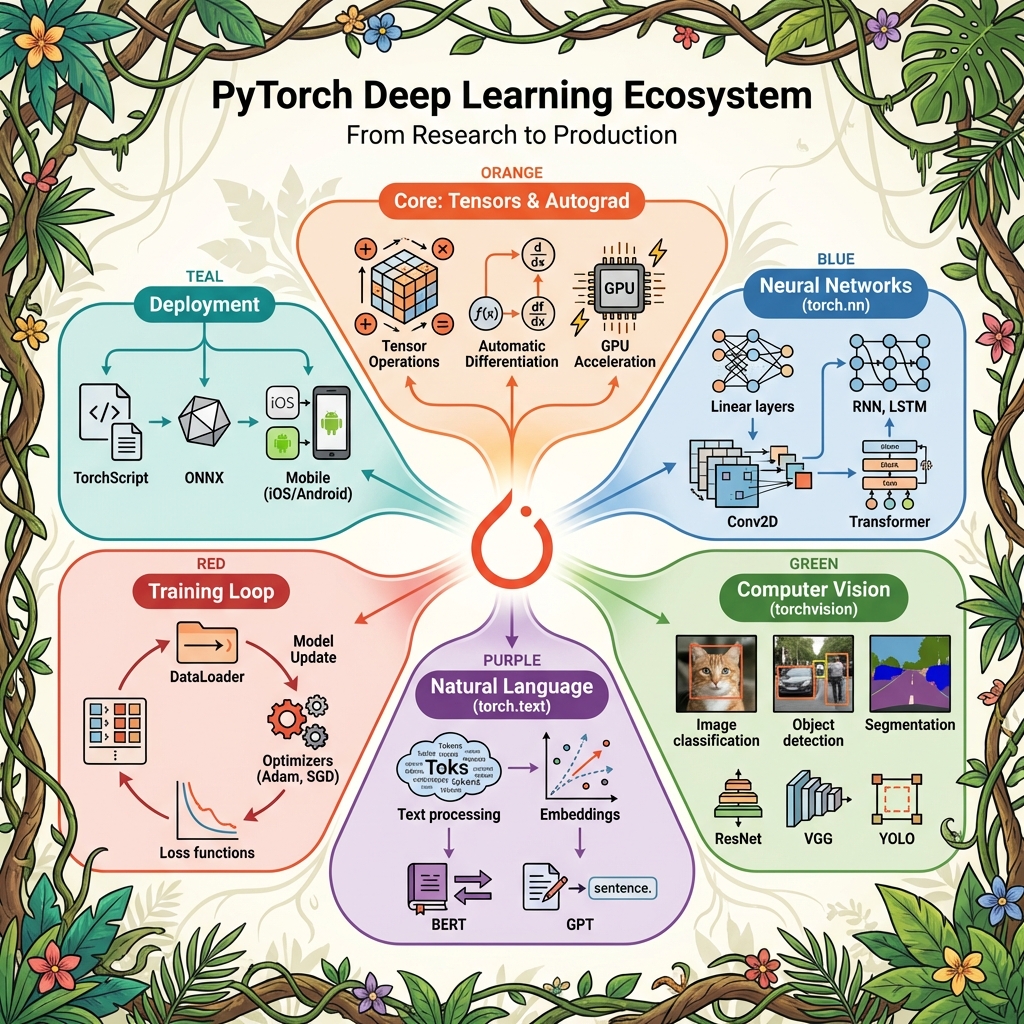
🧠 The Autoencoder: Learning What “Normal” Looks Like
An Autoencoder is a neural network that learns to compress data into a tiny representation, then reconstruct it. If the reconstruction is poor, the input was probably abnormal—it didn’t match the patterns the network learned.
NoteJargon Buster: How Autoencoders Work
An Autoencoder has two parts:
- Encoder: Compresses input (e.g., 100 features) into a small “latent space” (e.g., 10 dimensions)
- Decoder: Expands the latent space back to the original size (100 features)
Input (100) → [Encoder] → Latent (10) → [Decoder] → Output (100)Training: The network learns to minimize reconstruction error—the difference between input and output. It’s forced to learn the essential patterns because information must squeeze through the bottleneck.
Anomaly Detection: After training on normal data, feed in a suspicious sample. If reconstruction error is high, the sample is anomalous—it doesn’t fit the patterns the Autoencoder learned.
The Jungle Narrative: The Owl’s Memory Compression
The Owl can’t store raw sensor readings from every patrol forever—that’s terabytes of data. Instead, it compresses each patrol into a “patrol fingerprint” (the latent space). Normal patrols compress cleanly. But a patrol with unusual activity—say, a poacher using new tactics—produces a garbled fingerprint with high reconstruction loss. That’s the alert.
TipReal-World Example: Healthcare Provider Fraud Detection
Healthcare fraud costs the US over $100 billion annually. Insurers use Autoencoders to detect fraudulent provider billing:
- Input: 100+ billing features (procedure codes, patient demographics, claim amounts, referral patterns)
- Latent space: Compressed to ~10 dimensions
- Training: On millions of legitimate claims
- Detection: New claims with high reconstruction error are flagged for investigation
Why not Isolation Forest? Because billing patterns have complex correlations (certain procedures always accompany others). Autoencoders can learn these multi-dimensional relationships; tree-based methods struggle.
Technical Spotlight: Autoencoder in PyTorch
# Python: Autoencoder for Anomaly Detection with PyTorch
import torch
import torch.nn as nn
import numpy as np
# 1. Define the Autoencoder architecture
class Autoencoder(nn.Module):
def __init__(self, input_dim=100, latent_dim=10):
super().__init__()
# Encoder: compress 100 → 50 → 10
self.encoder = nn.Sequential(
nn.Linear(input_dim, 50),
nn.ReLU(),
nn.Linear(50, latent_dim),
nn.ReLU()
)
# Decoder: expand 10 → 50 → 100
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 50),
nn.ReLU(),
nn.Linear(50, input_dim)
)
def forward(self, x):
latent = self.encoder(x)
reconstructed = self.decoder(latent)
return reconstructed
# 2. Create sample data (normal + anomalies)
np.random.seed(42)
normal_data = np.random.randn(1000, 100).astype(np.float32)
anomaly_data = np.random.randn(10, 100).astype(np.float32) * 3 # Different distribution
# 3. Train on normal data only
model = Autoencoder(input_dim=100, latent_dim=10)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()
X_train = torch.tensor(normal_data)
for epoch in range(50):
optimizer.zero_grad()
output = model(X_train)
loss = criterion(output, X_train)
loss.backward()
optimizer.step()
print(f"✅ Training complete. Final loss: {loss.item():.4f}")
# 4. Detect anomalies via reconstruction error
def get_reconstruction_error(model, data):
with torch.no_grad():
reconstructed = model(torch.tensor(data))
error = ((reconstructed - torch.tensor(data)) ** 2).mean(dim=1)
return error.numpy()
normal_errors = get_reconstruction_error(model, normal_data)
anomaly_errors = get_reconstruction_error(model, anomaly_data)
print(f"🟢 Normal avg error: {normal_errors.mean():.4f}")
print(f"🔴 Anomaly avg error: {anomaly_errors.mean():.4f}")
# Output: Anomaly error is significantly higher!Key Insight: The Autoencoder was trained only on normal data. It has no idea what fraud looks like—but it knows what normal looks like. Anything that can’t be reconstructed well is suspicious.
🔗 The Encoder/Decoder Pattern: From Tiny to Massive
Here’s a surprising fact: the same Encoder/Decoder pattern powers both our tiny Autoencoder AND the massive GPT models that can write essays. The architecture is the same—only the scale differs.
WarningJargon Buster: Same Pattern, Vastly Different Scale
| Aspect | Our Autoencoder | GPT-4 / Claude |
|---|---|---|
| Purpose | Detect anomalies in numbers | Generate human-like text |
| Input | 100 numeric features | Text tokens (words) |
| Training data | 10,000 rows (your data) | Trillions of words (internet) |
| Model size | ~100 KB | ~70 GB – 700 GB |
| Runs where | Your laptop / Snowflake | Massive GPU clusters |
| Architecture | Dense layers (4 layers) | Transformer (96+ layers) |
Both use encode → latent space → decode. But GPT’s “latent space” encodes the meaning of language, while ours encodes normal billing patterns.
PyTorch is LEGO Blocks
Think of PyTorch (and TensorFlow) as a box of LEGO blocks. You can build:
- A small house (Autoencoder for anomaly detection) → No LLM needed
- A massive castle (GPT-scale language model) → Full LLM
Same blocks, different projects. The Owl uses the small house for patrol analysis. The Council’s scholars use the castle for interpreting ancient texts.
PyTorch = Building Blocks
Small Build (No LLM): Massive Build (LLM):
┌────────────────────┐ ┌────────────────────────────┐
│ Autoencoder │ │ Transformer (GPT, Claude) │
│ - 4 layers │ │ - 96+ layers │
│ - 1000s of params │ │ - Billions of params │
│ - Trains in mins │ │ - Trains for months │
│ - Runs on CPU │ │ - Requires GPU clusters │
└────────────────────┘ └────────────────────────────┘When to Use Each:
| Task | Tool | Why |
|---|---|---|
| Cluster customers by behavior | scikit-learn (K-Means) | Simple, fast, interpretable |
| Detect rare fraud in transactions | scikit-learn (Isolation Forest) | Tree-based, handles tabular data well |
| Detect complex anomalies in 100+ features | PyTorch (Autoencoder) | Learns multi-dimensional correlations |
| Classify images | PyTorch (CNN) | Neural networks excel at spatial patterns |
| Generate text / answer questions | LLM API (GPT, Claude) | Pre-trained on massive text corpora |
Concept Drift
Definition:
As wildlife migrates, seasons shift, or intruders adopt stealthier tactics, the statistical properties of sensor data evolve over time.
Adaptive Response:
Online or incremental learning allows the Owl’s models to update continuously without full retraining.
Outcome:
Even when poachers transition from loud trucks to near-silent electric bikes, the Owl continues to detect emerging threat patterns.
Failure Mode to Watch:
Concept drift is often “silent”—the system may keep producing confident outputs while accuracy degrades because the world has changed. This is why drift monitoring is typically paired with rolling-window evaluation (recent data vs. historical baseline), alert thresholds on error/uncertainty, and periodic calibration so performance doesn’t decay unnoticed.

Intelligent Patrol: Reinforcement Learning for Route Optimization
Dynamic Flight Paths
- Challenge: The Owl can’t be everywhere at once. It must plan routes for maximum coverage and minimal wasted energy.
- Technique: Reinforcement Learning (RL), where the Owl’s system tries different flight patterns, earning “rewards” if threats are detected, “penalties” if critical events are missed.
Why Reinforcement Learning:
Static or rule-based patrol heuristics work only in predictable environments. In dynamic settings like this jungle, threat locations, timing, and behavior evolve continuously. Reinforcement learning reframes patrol planning as a sequential decision problem, allowing the system to balance exploration (checking rarely visited areas) with exploitation (revisiting high-risk zones) while adapting its strategy based on observed outcomes.
Potential Multi-Agent Collaboration
- If desired, smaller scout drones or ground-based sensors can coordinate with the Owl using multi-agent RL.
- Ensures large swaths of jungle are covered efficiently, sharing data in real time.
Explainable AI: Trusting the Owl’s Judgment
Advanced sensing is crucial, but so is transparency about each alert:
Feature Attribution
- Highlights which sensor readings (thermal anomalies, suspicious sounds) triggered the Owl’s warning.
Saliency Maps
- Overlays the most relevant areas of an infrared image, showing rangers exactly where the Owl detected potential intruders.
Human-in-the-Loop
- Rangers can label false positives or confirm real incidents, refining the model incrementally. This clarity fosters confidence that the Owl’s advanced capabilities aren’t a “black box” but a collaborative tool.
Engineering Insight:
In practice, explainability is not only about user trust—it is a critical debugging tool. Feature attribution and saliency maps help engineers identify sensor failures, data leakage, spurious correlations, or drift-induced misbehavior. Many production issues are discovered not through accuracy metrics, but by inspecting why a model made a particular decision.
Practical Considerations
Energy & Coverage
- The Owl’s battery life and sensor ranges limit flight duration. RL-based optimization chooses which areas to prioritize nightly.
Ethical Boundaries
- Overly intrusive surveillance must balance with preserving wildlife privacy and not disturbing the habitat’s natural flow.
Continuous Maintenance
- Concept drift means the Owl’s software must be updated continuously—like routine calibrations to keep sensors accurate.
Edge vs. Base Station
- Some data is processed onboard (edge AI) to reduce latency; heavy training or updates may occur at a protected station.
Key Takeaways
Sensor Fusion: Blending infrared, acoustic, and chemical data yields a panoramic view of the jungle—vital when intruders adopt stealthy tactics.
Anomaly Detection & Concept Drift: Detecting outliers and updating models for changing conditions keeps the Owl nimble in a dynamic environment.
Reinforcement Learning: Intelligent route planning maximizes coverage with limited resources, allowing the Owl to safeguard wide territories.
Explainable AI: Clear justifications of each alert build trust in the Owl’s vigilance, especially in sensitive conservation efforts.
Balanced Deployment: Effective system upkeep, ethical considerations, and respect for nature’s rhythms ensure advanced AI remains a force for good.